
This is the first of a series of posts exploring the multi-terabyte publicly available Global Database of Events, Language, and Tone (known as GDELT). I originally completed a version of this analysis as the final project of a Machine Learning course in my Master’s program at Georgia Tech. The full project consisted of several Natural Language Processing (NLP) techniques including a Multinomial Naive Bayes classifier to predict US TV news stations, a station Similarity Index to compare and contrast news stations, Latent Semantic Analysis for Dimensionality Reduction, and Topic Discovery via Gaussian Mixture Model and Expectation Maximization. I broke the project down into smaller individual components for discussion on this site so readers can more easily explore the topics of greatest interest (and to make it a bit easier to organize my thoughts). In this post, I outline high-level goals for the project, give some background on GDELT, and discuss my choices for accessing and manipulating the data in Google Cloud Platform.
Sections
- Introduction
- Global Database of Events, Language, and Tone (GDELT)
- Google Cloud Platform (GCP)
- Conclusion
Introduction
I often feel that “unbiased news coverage” is a contradiction in terms, and according to the 2021 Edelman Trust Barometer, I’m not alone in this feeling. According to this online survey of 31,050 global respondents, 59% agree with the statement that “most news organizations are more concerned with supporting an ideology or political position than with informing the public”.
I wanted to use Natural Language Processing techniques to probe this intuition and explore questions like:
-
Can a model accurately classify a US TV news station based on transcripts of the station’s broadcasts (even if obviously identifying information were removed)? If a model can learn to detect characteristic vocabularies and phrasings on news stations, it may suggest the stations are not simply providing a straightforward presentation of the facts.
-
Based on their use of language, which TV news stations are most similar to one another? Which differ the most?
-
Can a model automatically discover the “top headlines” or key topics on news stations in a given week? If so, can the model estimate how heavily each station covered each topic?
This post focuses on the main data source for my analysis, the Global Database of Events, Language, and Tone and my decisions around accessing and working with the data.
Global Database of Events, Language, and Tone (GDELT)
Supported by Google Jigsaw, the GDELT Project monitors the world’s broadcast, print, and web news from nearly every corner of every country in over 100 languages and identifies the people, locations, organizations, themes, sources, emotions, counts, quotes, images and events driving our global society every second of every day, creating a free open platform for computing on the entire world.
Background
GDELT is a massive database consisting of multiple terabytes of data. GDELT encompasses several distinct datasets, and for this project I focused on the Televison News Ngram 2.0 Dataset. The dataset is generated through an automated process which monitors the Internet Archive’s Television News Archive and parses the full-text “closed caption transcriptions from US TV News shows”.
N-Gram Data
A common approach to Natural Language Processing (NLP) involves splitting a body of text or “corpus” up into groupings of distinct ordered words or “tokens”. These groupings are called N-Grams. The “N” denotes the size of the grouping: groupings of size 1, 2, and 3 are referred to as “unigrams”, “bigrams”, and “trigrams” respectively. By counting the number of occurences or “frequency” of each N-Gram within a corpus, we can build probability distributions which may be useful in characterizing the corpus or making predictions about previously unseen text.
GDELT parses TV transcriptions into unigrams, bigrams, trigrams, 4-grams, and 5-grams with associated frequencies at 10-minute intervals for the following TV News stations:
- ABC
- Al Jazeera
- BBC News
- Bloomberg
- CBS
- CNBC
- CNN
- CSPAN
- CSPAN2
- CSPAN3
- Deutsche Welle
- FOX
- Fox Business
- Fox News
- LinkTV
- MyNetworkTV
- NBC
- MSNBC
- PBS
- Russia Today
- Telemundo
- Univision
A small example of the unigram data is shown here:
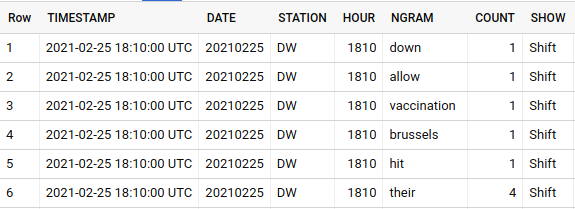
Well over a terabyte of data is available, with N-Grams going back to 2009 for most of the available stations. Over a million records are generated each day across all stations.
Google Cloud Platform (GCP)
GDELT datasets are publicly available. Through a partnership with Google, the N-Gram data are published and hosted in an easily-accessible format in GCP.
Google BigQuery
Since the N-Gram data were already being conveniently hosted in GCP, I chose to work with the data within the Google cloud environment.
BigQuery is Google’s “serverless, highly scalabe, and cost-effective multicloud data warehouse”. BigQuery’s Cloud Console UI makes it easy to explore visually and through basic SQL queries.
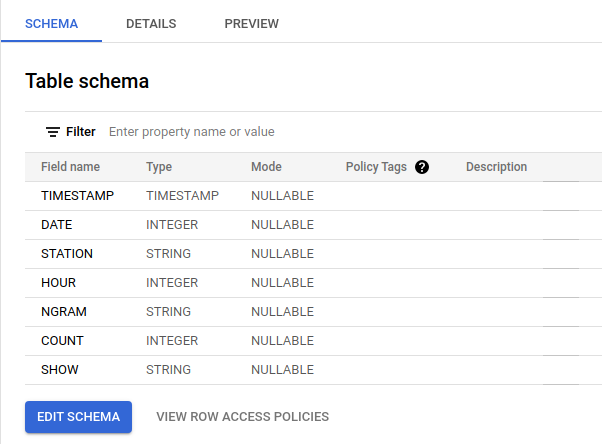 Exploring the GDELT unigram schema in BigQuery Cloud Console
Exploring the GDELT unigram schema in BigQuery Cloud Console
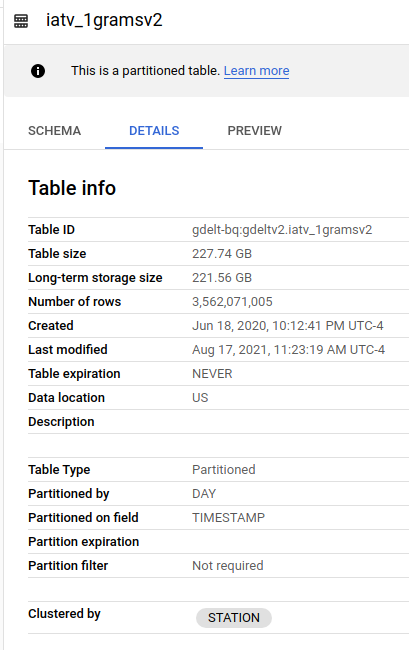 GDELT unigram table details
GDELT unigram table details
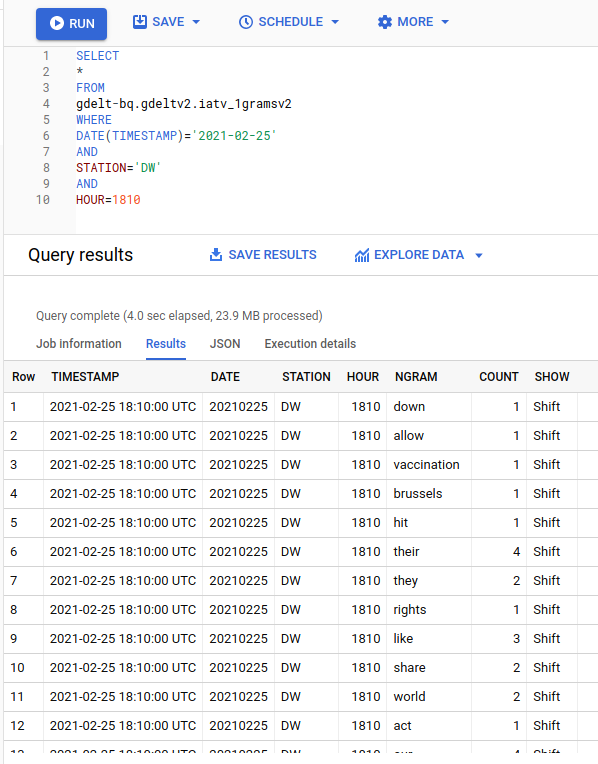 A simple query exploring some records in the GDELT unigram table
A simple query exploring some records in the GDELT unigram table
Google AI Platform Notebooks
While BigQuery provides fast and easy access to the N-Gram data, I knew that further cleaning and transformation would be required before the data could be used to build models. Python is my favorite language for these tasks, so I wanted a Python environment with the following requirements:
- Easily and cost-effectively access/extract data from Google BigQuery
- Sufficient memory and compute resources to process and manipulate at least 1 week of N-Gram data
- Key packages pre-loaded or easily installed (NumPy, pandas, matplotlib, and scikit-learn for starters)
Nice-to-haves:
- A REPL/notebook interface to weave code with figures, program outputs, and written text
- Ability to scale storage and compute resources up or down as needed
At first, I considered using Google Colaboratory, a free Google-hosted Jupyter Notebook environment. However, the free tier of Google Colab is resource-constrained, and I was concerned that these constraints may prevent me from quickly and easily experimenting with larger subsets of data if needed.
In the end, I opted to use a Google AI Platform Notebook environment. Its tight integration with BigQuery, easily scalable configuration of CPU, RAM, and GPU resources, and out-of-the-box support for the most common machine learning packages met all of my requirements for the project and enabled me to get up and running in a few minutes.
Here’s a walkthrough of the notebook setup process:
 The AI Platform Notebook management UI
The AI Platform Notebook management UI
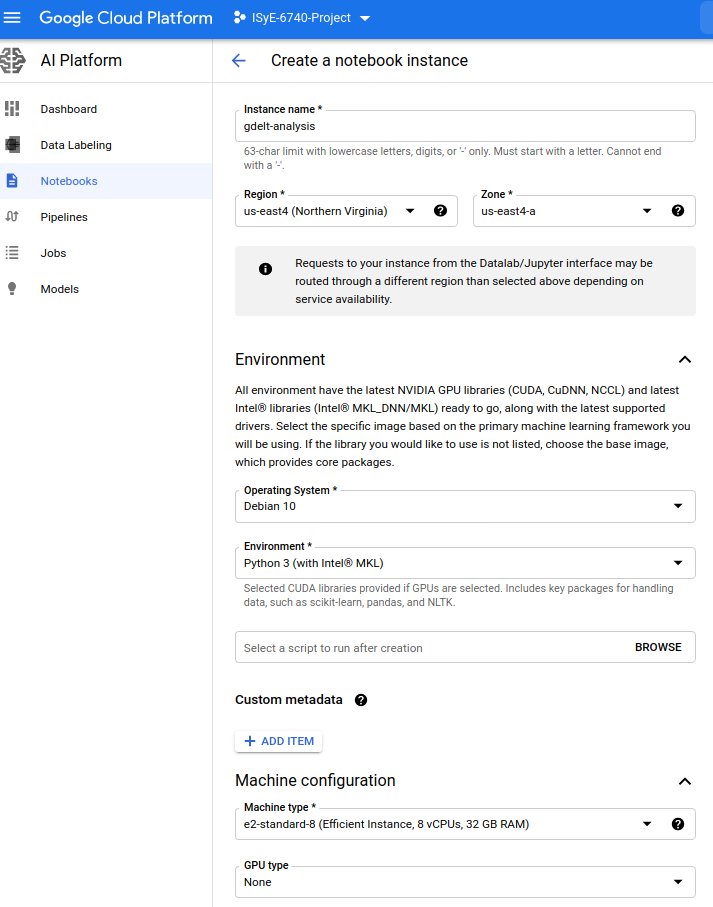 Creating a new notebook environment
Creating a new notebook environment
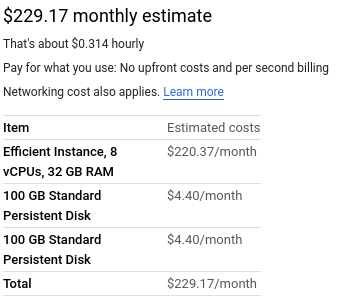 A rough cost estimate for the notebook environment, assuming the notebook is left on and running all the time. If I’m mindful to shut off the notebook environment when not in use and delete the environment when the project is done, costs shouldn’t exceed $10 or so.
A rough cost estimate for the notebook environment, assuming the notebook is left on and running all the time. If I’m mindful to shut off the notebook environment when not in use and delete the environment when the project is done, costs shouldn’t exceed $10 or so.
 The new notebook environment, now available to access from the management UI
The new notebook environment, now available to access from the management UI
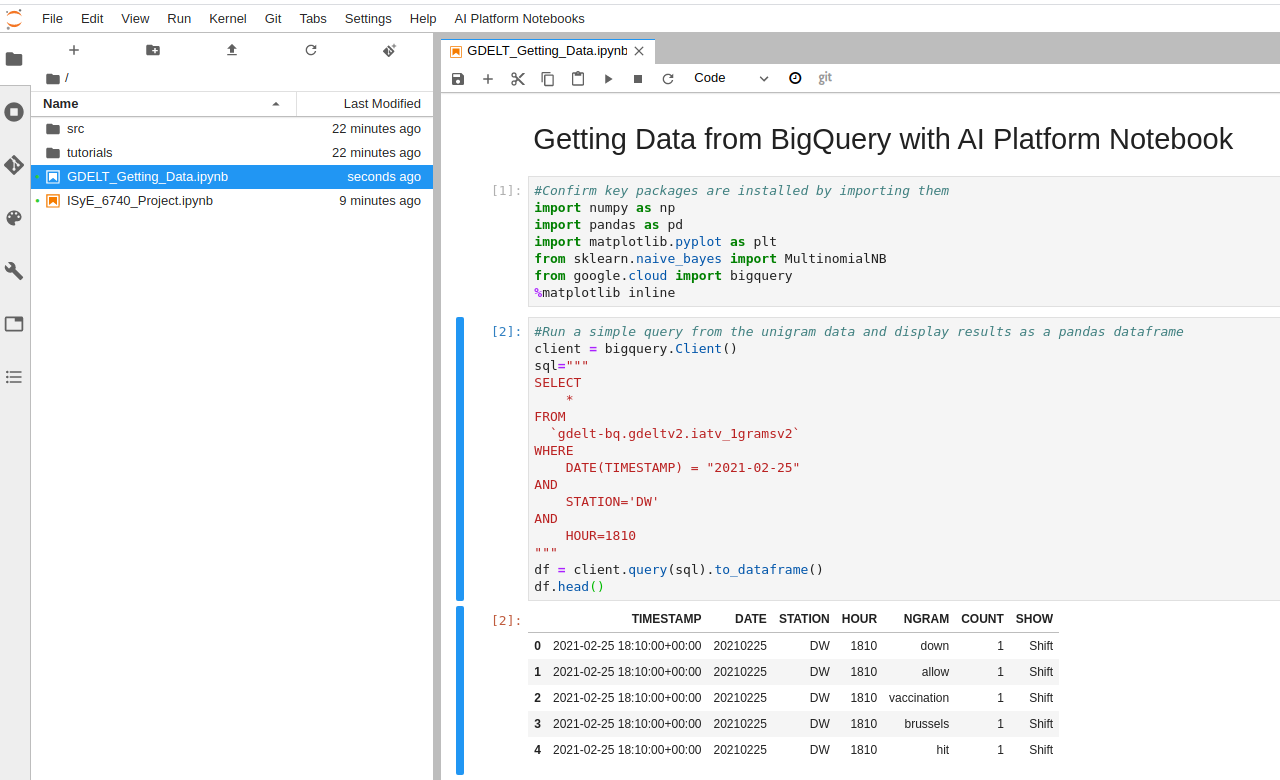 The final notebook, demonstrating the ability to import the necessary packages, query the unigram data from BigQuery, and display the results as a Pandas dataframe.
The final notebook, demonstrating the ability to import the necessary packages, query the unigram data from BigQuery, and display the results as a Pandas dataframe.
Conclusion & Next Steps
In this post, I outlined the key questions I aimed to explore in the project, gave some background on the data source I used within GDELT to conduct the analysis, and discussed the environment I set up in GCP to access and manipulate the data. In the next post in this series, I’ll discuss Data Cleaning and Transformation. Additional posts will cover the theory and implementation behind a Multinomial Naive Bayes Classifier, a station Similarity Index to compare and contrast news stations, Latent Semantic Analysis for Dimensionality Reduction, and Topic Discovery via Gaussian Mixture Model and Expectation Maximization to detect headlines. As I add posts, I’ll circle back to this page to add links, and all the posts in the series will be linked to the ‘GDELT’ tag available here
){kind=link}